Shuo WanginTowards Data ScienceConvergence in Probability or DistributionWhat is the difference between the two?·6 min read·Sep 4, 2023----
Shuo WanginTowards Data ScienceFind Missing Index: In-placeHow to find the first missing integer in an array without using extra space·5 min read·Dec 26, 2021----
Shuo WanginTowards Data ScienceK-means clustering: find my tribe!How does it work? How can I make it run faster?·12 min read·Sep 13, 2021----
Shuo WanginGeek CultureThree Sum: Love TrianglesHow to find three sums most efficiently·6 min read·Aug 23, 2021----
Shuo WanginGeek CultureSliding Window MaximumAn analysis of algorithms and complexities·5 min read·Jun 1, 2021----
Shuo WanginTowards Data ScienceCombinatorial Optimization: The Knapsack Problem·8 min read·May 17, 2021----
Shuo WanginCodeXBlending Signals for Portfolio ConstructionBenefits of portfolio diversifications·5 min read·Apr 16, 2021----
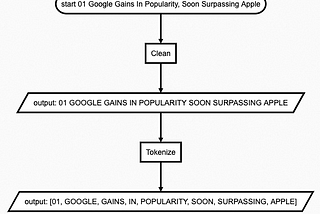
Shuo WanginTowards Data ScienceStarting Natural Language ProcessingExploring the basics of NLP: Cleaning, NER, POS, Fuzzy String Match·5 min read·Feb 22, 2021----
Shuo WanginTowards Data ScienceLargest Rectangle in a MatrixHow to combine programming techniques·7 min read·Jan 17, 2021----